要不要跟 AI 说英文
Published: 2025-08-04

请问 LLM 的 token 是怎么计算的?假如我在使用 chatGPT 或者 Claude 的时候,我应该跟它说中文,还是说英文?我想知道人类输入的语言是否会影响 LLM 的理解,还有就是不同的语言是否会需要更多的消耗,带来更多的成本
LLM 的 token 是怎么计算的
现在的主流大模型(GPT-4、Claude、Gemini 等)都先把输入文字做「tokenization」——把字符拆成“token”。 OpenAI 用 tiktoken,Claude 用自家 BPE,Gemini/Llama 用 SentencePiece。
经验上:
– 英文平均 1 token ≈ 4 个字符 ≈ 0.75 个英文单词。
– 中文、日文等 CJK 文字因为 UTF-8 字节更长,通常一个汉字≈2-3 token,整句会比同长度英文多出 1.5-2.5 倍 token。
想精确算,可直接把文本贴到官方或第三方计数器(如 llmtokencounter.com、token-calculator.net)查看对应模型的 token 数。
有一些线上的工具,可以输入一段文本内容,然后看到 tokenization 的结果。比如这个 revechat 的 token calculator,
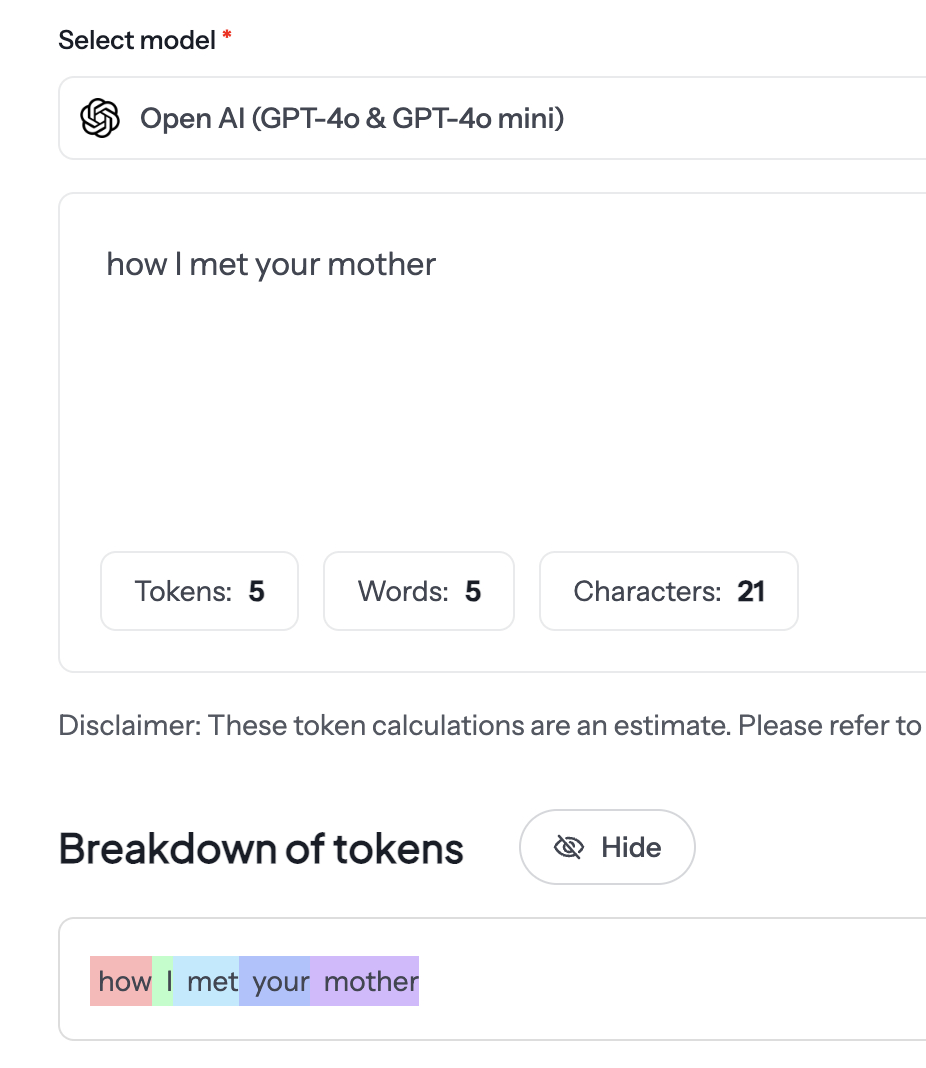
可以看到 token 的数量其实跟字母的数量不一定是一一对应的关系。How I met your mother 里有 21 个英文字母,一共只消耗了 5 个 token.
中文的 老爸老妈浪漫史,7 个汉字最后换算出来是 7 个 token.
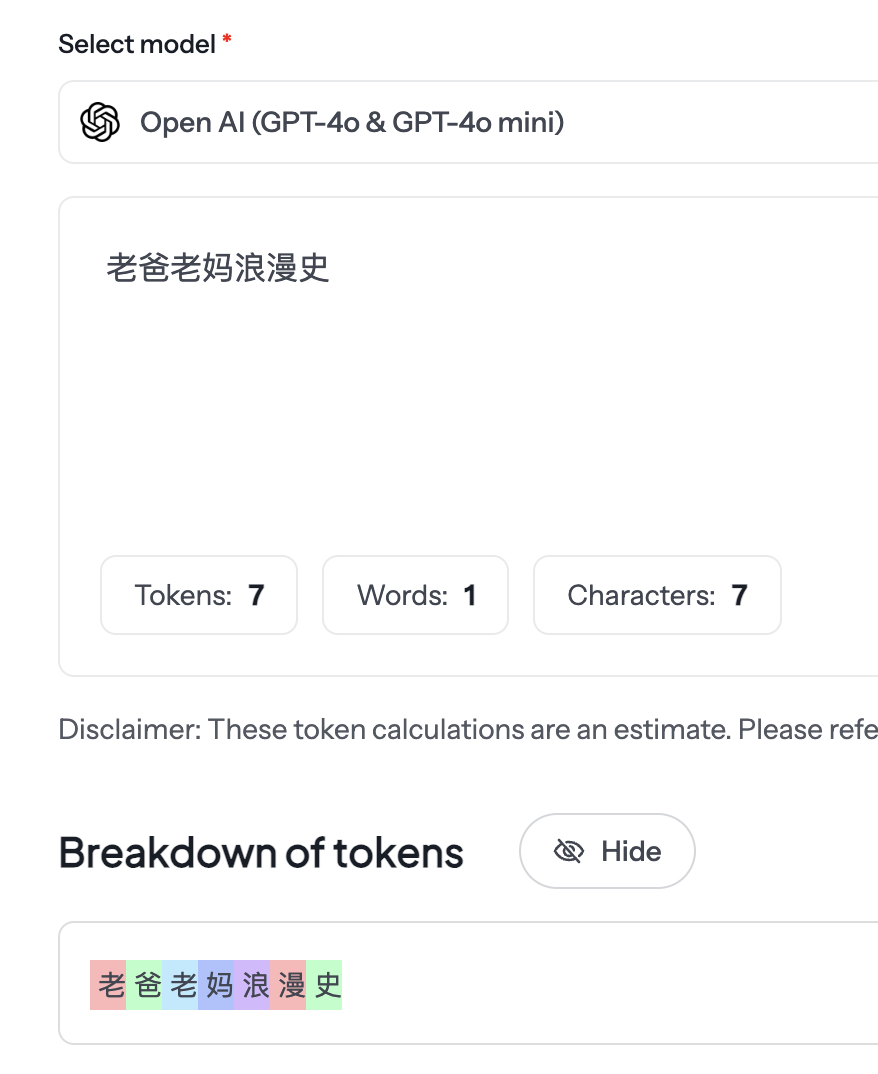
这里只是举例,没有说这里的中文和英文是十分贴合对应的意思,只是刚好脑子里想出来了这句话。
而且这里不同的语言还会有不同的区别。有一篇来自 Yennie Jun 的关于这个话题很好的文章,all languages are not created tokenized, 里面写到:
This process of tokenization is not uniform across languages, leading to disparities in the number of tokens produced for equivalent expressions in different languages. For example, a sentence in Burmese or Amharic may require 10x more tokens than a similar message in English.
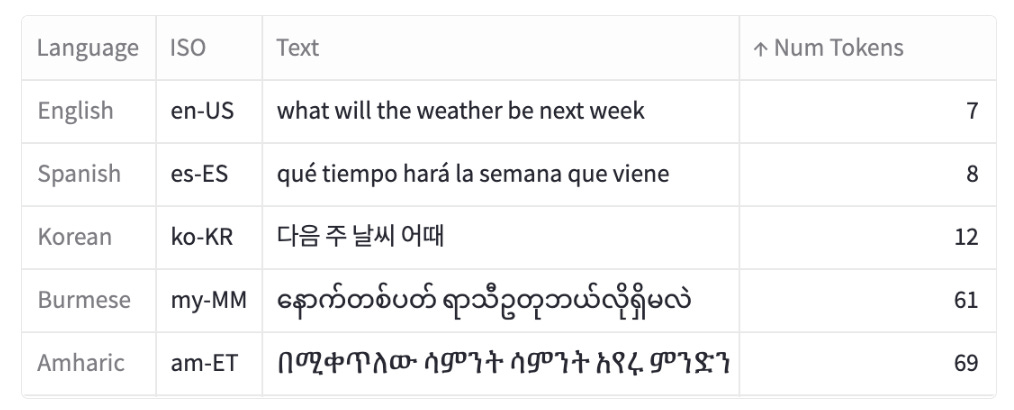
我的感想是,所有的语言都很美丽,但有的语言比其他的语言更贵 lol
回到最开始的问题,说中文还是说英文更划算?
成本:API 按 token 计费。以 OpenAI GPT-4o 为例,1 M token 输入 $5、输出 $20;中文因 token 多,同样字数成本比英文高 50-100%。
性能:训练语料以英文为主,英文任务通常更准、更快;小语种(如泰语、缅甸语)不仅 token 膨胀,还可能生成速度慢、质量低。
结论:
– 如果你追求最低成本且英文水平 OK,用英文提问最经济。
– 如果问题本身就是中文语境,或你的英文表达受限,直接写中文即可,额外费用在可接受范围,且 GPT/Claude 对中文的理解已相当不错。
一句话总结:
“英文 token 少→便宜,中文 token 多→稍贵;但模型对两种语言都能理解,按你最能清晰表达的语种来就行。”
虽然中文 tokenise 后的 token 更多,但中文是一种信息密度比较高的语言。表达同样的意思,中文需要的字符更少,而且我们是中文母语者,没有经过训练的情况下很难用简短干练的英文表达自己。考虑到这点到话,结论会有什么变化吗
通常还是英文更省 token(即更省钱),只是“贵多少”被稀释了一些;
量化对比
信息密度:
语言学里用“每字符信息量(bits/char)”衡量,现代汉语≈8.0 bits/char,英语≈4.5 bits/char。
也就是说,表达同一句话,中文需要的字符数大约是英文的 4.5/8.0 ≈ 0.56 倍。
Token 密度:
英文平均 1 token 对应 4–5 个字符。
中文平均 1 token 对应 1.2–1.5 个字符(一个汉字本身≈2–3 token,因为 UTF-8 编码 + BPE)。
因此,中文的 token/char 比例大约是英文的 3–3.5 倍。
综合两个因子
token(中文) / token(英文) ≈ (字符比) × (token/char 比) ≈ 0.56 × 3.2 ≈ 1.8
即:
对同一段语义,中文最终 token 数大约比英文多 60–100%。
信息密度高只能把 “2.5 倍” 拉到 “1.8 倍”,但并未抹平差距,因此英文仍然更便宜。
什么时候有例外?
专有中文术语、诗词、成语或法律条文,中文极度凝练,可能让字符比进一步降到 0.3–0.4,此时成本差异缩小到 < 50 %。 反之,英文里出现大量缩写(AI, DNA, USB)时,英文 token 数还可能再降,差距重新拉大。
建议
若追求极致省钱,且你能用英文准确描述,优先用英文。 如果中文表达更简洁、准确(或你更擅长),不必因成本而勉强转英文——额外费用通常只是几厘钱,不值得牺牲清晰度。
我觉得还要考虑自己使用 AI 的场景,如果是写程式,本身很多的上下文就已经是英文了,倒不如尽量使用英文。反正 AI 不会挑语法或者拼写的错误,而且自己也不需要频繁切换语言。好处多多。
disclaimer: 本文是我和 Kimi 的聊天整理出来的,没有做太多 fact check. 就是自己想知道着玩。